
Beyond RAG: Why We Chose Long Context Processing For Your Government Work
Reading time: 6 minutes

RAG (Retrieval-Augmented Generation) has been a go-to solution to overcome the limits of earlier LLMs, especially their small context windows. But in just one year, models like GPT-4 have expanded their context capacity from 8,000 to 128,000 tokens — a 16-fold leap. Others, like Claude and Gemini, can even process hundreds of thousands of words at once.
These advancements make it possible to analyse entire documents using Long Context Processing, offering deeper understanding and synthesis. While RAG remains effective for targeted searches, it is no longer the default answer for every task. By challenging the 'RAG-fits-all' mindset, we're optimising your LLM tools for the nuanced demands of your work.
Understanding RAG and Why We're Moving Beyond It
Think of RAG as an efficient librarian who can quickly locate specific passages across thousands of books in a massive library - great for fact-finding, but potentially missing broader connections.
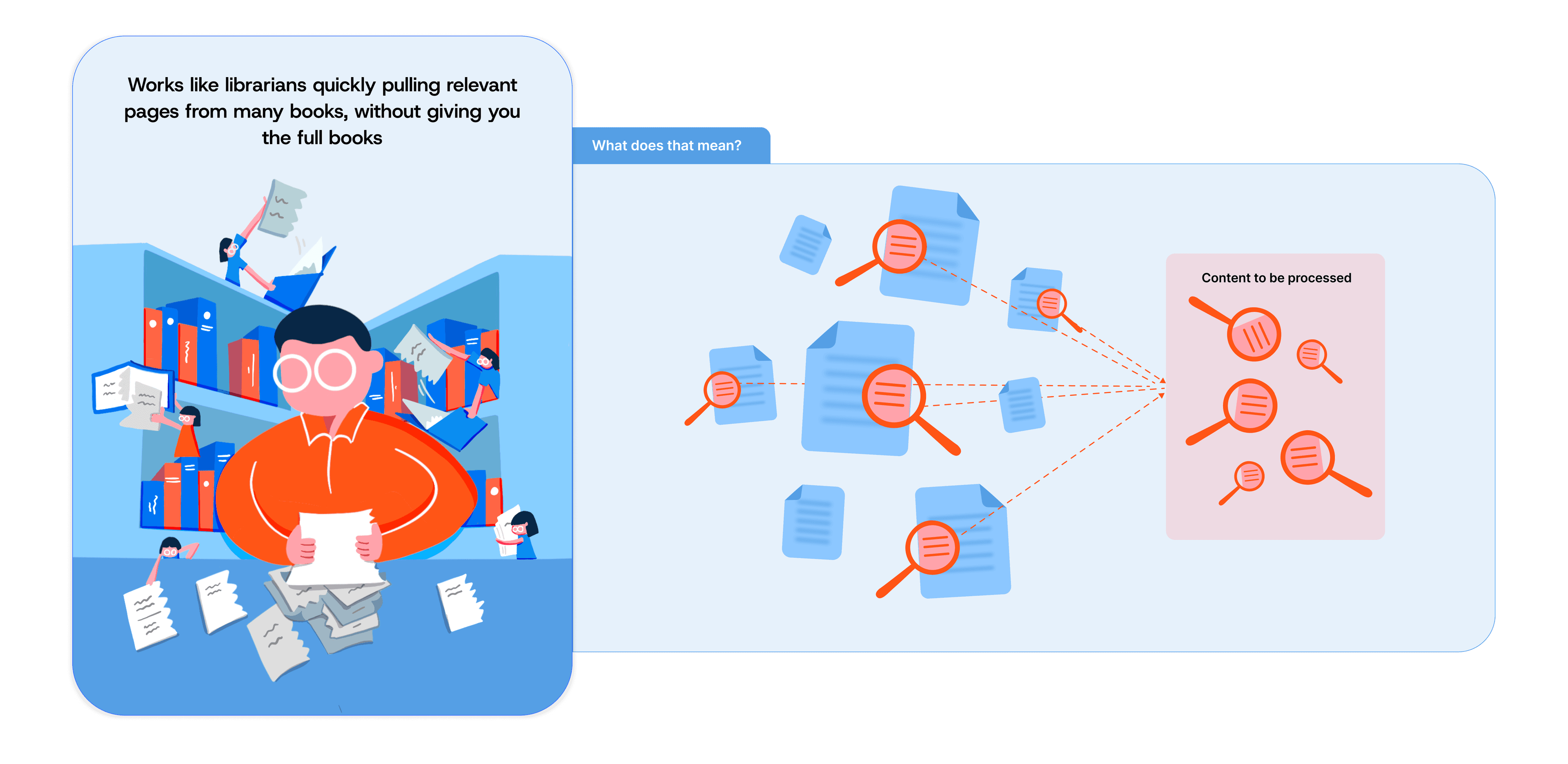
Here's what a successful RAG system does well:
- Broad Searches on Large Datasets: RAG is great at searching through large collections of documents - especially if you have a set structure to these documents like court judgments or legislations.
- Cost Effectiveness: RAG is like giving the LLM only the relevant pages from all the books in a library. This means the LLM processes less information, which makes it cheaper to run.
- Citations: RAG has citations systems that can provide you with specific citations and references.
Still, RAG isn't perfect, and getting every piece of the system working well is challenging. Let's look at where it might stumble:
1. The Need for Customisation
A successful RAG system needs to be tailored to your specific needs. While LLMs naturally understand context and language nuances, RAG is more mechanical - it's basically playing a sophisticated numbers matching game without understanding the full context or the relationships between different pieces of information.
Without careful design of how documents should be read, organised, and interpreted, a generic RAG setup will often miss important connections and context. This is why one-size-fits-all solutions typically fall short, as each RAG component needs to be optimised for your specific use case.
2. Synthesis and Analysis
RAG is great at finding specific pieces of information but isn't designed to analyse or synthesise insights across multiple sources. It retrieves relevant data based on your query but doesn't connect the dots or build a bigger picture - like reading specific pages of a book without reading the rest of the book.
For example, if you're investigating customer feedback trends, RAG might pull specific comments or survey results but won't combine them into an overall pattern or conclusion. It focuses on the retrieved details, but not interpreting or summarising them in a broader context of the documents.
3. Dependent on Data Quality
RAG is highly reliant on the quality of the data it works with. If documents are not standardised—meaning they use different formats, terminology, or structures—RAG may struggle to understand and organise the information meaningfully. This can lead to irrelevant or incomplete search results.
Examples of standardised datasets can include:
- FAQs with clear section headers, questions and answers.
- Hansard Parliamentary Reports with consistently labelled metadata and document structures.
💡 RAG for Pair Search: Learning From Experience
Did you know that Pair Search indexes ~58,000 documents? Such a large database means it's an excellent use-case for RAG!
When building Pair Search, we discovered that RAG works best when tailored to your specific needs - like having a custom-fitted suit rather than one off the rack. With Hansard Parliamentary Reports, we designed every aspect - from how we read and organise the documents to how we interpret search queries.
This custom approach helped us build a system that truly understands our dataset to improve its accuracy.
Enter Long Context Processing
Long Context Processing takes a different approach - made possible by the advancements in LLM's context capacities. Instead of retrieving specific sections, it processes entire documents at once.
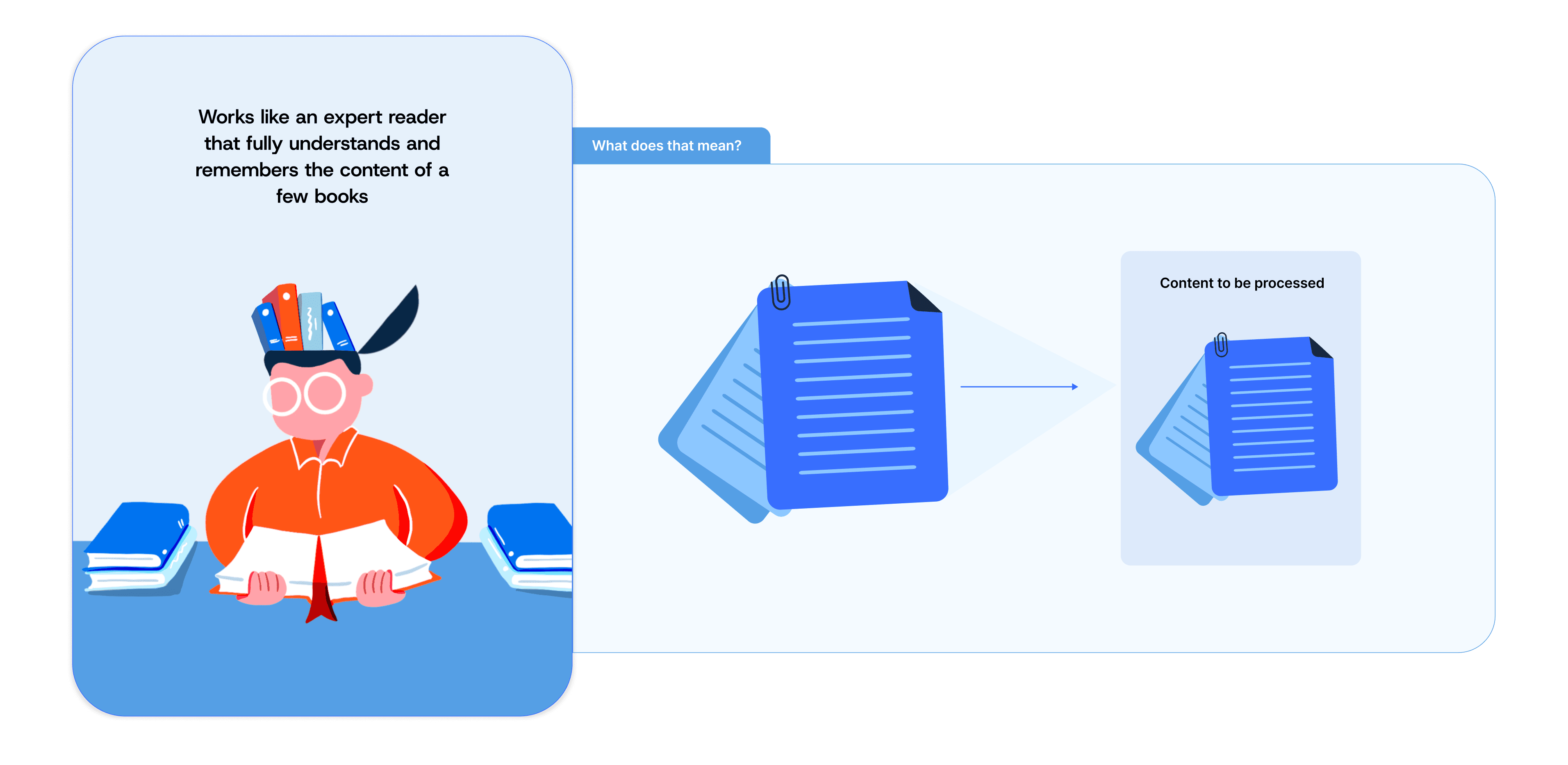
This comprehensive view enables deeper understanding and more nuanced analysis, crucial for government work. It's like having an expert analyst who can read, understand, and synthesise all the information from multiple complex documents - rather than just reading specific sections from these documents.
Here's where Long Context shines:
- Holistic Understanding: Long Context Processing enables the LLM to stay aware of the entire document, making it easier to uncover nuanced insights and connections that might otherwise be overlooked in isolated sections.
- Thorough Analysis and Summary: With full context at hand, the LLM can dive deeper into complex documents, identifying subtle interactions and implications across the text.
- Consistency Checking: By processing the full documents rather than isolated sections, the LLM can spot inconsistencies or contradictions that might appear in different sections.
Consider a 100-page healthcare policy proposal: While RAG might efficiently locate sections about “preventive care,” Long Context Processing can identify how that definition affects funding allocations fifty pages later, catching potential policy implications that isolated searches might miss.
Choosing the Right Tool for the Job
| RAG | Long Context | |
|---|---|---|
| How it works |  Pulls specific sections when queried based on mechanical matching Pulls specific sections when queried based on mechanical matching |  Reads the full documents Reads the full documents |
| Context Awareness | Awareness of specific sections based on how the retrieval was done | Maintains awareness across entire documents |
| Best for |
|
|
| Sample Use Cases | Customer Support Q&A based on a set of FAQs Pair Search - Searching through Hansard | Synthesising different countries' policies on a certain topic Analysis of trends and patterns |
| Struggles With | Prone to hallucinations and fragmented understanding - especially for generic RAG implementations | Relies solely on the LLM model for processing |
💡 A Note on Hallucinations
Think of RAG like trying to answer questions about a book when you've only read selected paragraphs. Without full context, even the best systems might make incorrect assumptions about the missing pieces. While generic RAG implementations can quickly find information, they're more prone to these hallucinations than Long Context processing, which works with complete documents.
Our Focus: Helping You Work Better
At Pair, we believe government work deserves precision and accuracy. While RAG might seem more sophisticated, generic implementations tend to hallucinate and lose accuracy. In contrast, even simple Long Context approaches deliver coherent, accurate insights.
That's why we started with Long Context processing for Pair Chat—it's the best way to ensure every nuance and connection is captured across complex documents and diverse use cases.
Whether you're drafting legislation, analysing policy papers, or coordinating inter-departmental memos, our approach helps you grasp the full picture and identify subtle implications that might otherwise be missed.
The Road Ahead
As the technology evolves, we're seeing exciting developments like Long RAG (combining comprehensive understanding with efficient retrieval), more sophisticated reasoning models for RAG, and other hybrid systems that leverage the best of both approaches.
While we started with Long Context, we're actively exploring these new approaches to help you get the right tool for your job. This could mean:
- Continuously increasing our context window to handle even larger documents
- Exploring approaches that combine the strengths of both long context and RAG
- Developing bespoke tools to help you determine the best approach for your specific needs
💡 Have a specific use case that might benefit from a custom RAG implementation?
Contact our Support Team.
Our focus remains simple: providing the most reliable tools for your work, backed by rigorous testing and real-world results.
And as always, we're free to use!
Built by:

© 2024 Open Government Products